
Bridging the Two Worlds, Part 1
This is the first in a series of articles in which we will explore the opportunities that can be accomplished by connecting these two related, yet inherently disconnected worlds. The series will navigate the Operational Change Management Maturity Levels to provide a pathway towards reducing incidents and outages, and avoid inflicting unnecessary pain to ourselves.
The series does not cover the change management process itself. There is plenty of content available that explores the change management discipline. We will explore what is limiting the benefits promised by the change management process from directly helping infrastructure operations; and how these challenges can be overcome.
explores the change management discipline. We will explore what is limiting the benefits promised by the change management process from directly helping infrastructure operations and how these challenges can be overcome.
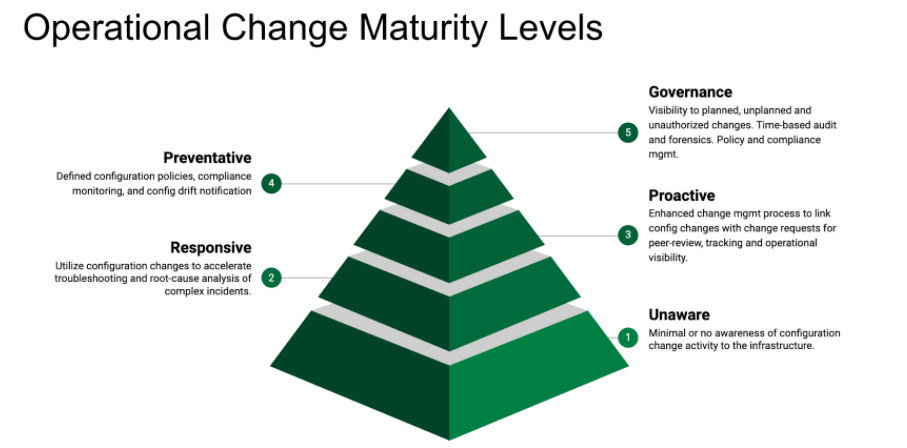
Level 1- Unaware
“More than 80% of all incidents are caused by planned and unplanned changes” – Gartner
Of all the wild claims we often hear from industry analysts, this particular one rings true. We could debate the percentage value, but the core essence of the statement is accurate. There’s a reason why most industries that are highly dependent on their IT infrastructure and services such as financial services, retail, etc… go into a “lock-down” mode during their seasonal peaks —making changes breaks things.
But aren’t we supposed to “fail fast” and “break things” now?
Amazon, Google, and Netflix dominate because of their ability to innovate quickly. They adopted the “fail fast” mentality and created a culture that do not adversely penalize mistakes for the sake of innovation. This is often measured by the number of successful change requests. In some ways, the ability to promote changes and improvements directly correlates to their business agility.
But how do you do this at scale? How does an organization reduce the risk and make more frequent changes manageable? Many look towards infrastructure as code or software-defined X as the goal. However as many developers can attest, just because it is “code” i.e releases are automated, does not eliminate the underlying issues. Organizations need to revise their perspective on what managing changes means to them, specifically the discipline and process required to reduce the risk. There are light-weight strategies teams can adopt to help avoid causing pain.
The good news is that software developers have been dealing with quality assurance for a very long time. The opportunity is in applying the lessons to help infrastructure operations.
What does “Level 1- Unaware” mean?
Here’s the scenario:
- A critical business application or service breaks
- You would hear “What the #$&% changed ?!?”
- The technician starts looking at the availability dashboards to see if there is any outages
- Checks the alerts to see if there are any related events
- Checks the performance charts to see any symptoms
- Sets up a bridge across the functional teams to see if it’s a network, server, storage, application, cloud, or security problem
- Then the inevitable…start digging down into logs to find the needle in the haystack
But what’s missing? In this scenario, we rarely experience the technician search Change Requests (CRs) to see if there were recent changes that may have caused the problem. The technician is busy looking at symptoms and trying to guess the cause vs assessing relevant changes that have recently occurred that might have caused the problem. Both approaches are needed however, understanding changes can tremendously narrow the search-space and reduce the time to repair.
Change Requests are often not utilized because they lack actual detailed configurations that resulted from the work. CRs describe the work to be carried out and can provide detailed instructions on how to perform the work, but they do not capture the resulting configurations needed to troubleshoot and repair problems by the infrastructure monitoring team. This is the disconnect or gap between those implementing changes to the infrastructure vs those monitoring and keeping everything up and running.
Additionally, many organizations still struggle to adopt a consistent change management process. Frequently changes are made directly to systems and devices without following the change request process. These unplanned changes are often the source of outages. Without visibility and accountability to these ad-hoc or unplanned changes, it is very difficult to instill these process changes.
Lastly, unauthorized changes or security breaches, both internal and external are becoming common-place. It’s not a matter of if but when this will occur. How do you know if you’re compromised if you don’t even know what changes are going on?
These symptom highlights a couple of key limitations in managing change:
- Change Requests do not contain sufficient technical details to help narrow down the root-cause of complex incidents. They do not contain the actual configuration of systems or devices resulting from the execution of the change request.
- Operations monitoring does not have visibility to configuration changes that are taking place, including planned, unplanned changes and unauthorized.
What’s Changed?
How do operations answer this question today? The answer is … complicated.
First, it depends on what functional domain (aka silo) you’re referring to. Is it network configuration changes, servers, applications, storage, cloud, or security? In addition, each of these are likely to have their own management tool to configure their elements. Some may have multiple, where one application team uses Ansible, another may prefer Puppet.
All of these disparate tools only show part of the picture which makes it difficult to really understand how independent changes in each functional group can impact each other. Hence the need for the conference bridges to isolate the root-cause of complex outages are common-place. No wonder we frequently hear of outrageous hourly outage costs.
According to Gartner, the average cost of IT downtime is $5,600 per minute. Because there are so many differences in how businesses operate, downtime, at the low end, can be as much as $140,000 per hour, $300,000 per hour on average, and as much as $540,000 per hour at the higher end.
A critical requirement to improve change management for infrastructure operations is “change monitoring”. You need the ability to quickly review configuration changes across all IT infrastructure and easily search for relevant configurations and changes all in a single place.
The change monitoring tool must be flexible. Depending upon your environment, it may be needed to support a plethora of complex services and devices as well as the nuances of legacy systems. For a Communications Service Provider (CSP), this can range from fiber equipment and 5G Radio Access Network (RAN) equipment, to new SDN virtual devices. For a new SaaS provider, it needs to be Cloud services aware (AWS, Azure, GCP), supports containers and orchestration. For enterprises, Hypervisors, SANs and all of the above.
The above is simply just getting the data. Making it easy for operators to get the needed information at their fingertips is entirely another challenge.
Conclusion
Change management is more than just managing the approval process and execution of changes. It must also involve the monitoring of changes to bring visibility and accountability to planned, unplanned and unauthorized changes. Once you have this in place, you can then start to take actionable steps towards improving infrastructure operations.
Next in the series we will cover “Level 2 – Responsive” and discuss in greater detail how configuration change monitoring can help accelerate root-cause analysis of complex incidents.
—
For more information on “What the #$&% changed ?!?”, please contact SIFF at:
[email protected]
https://siff.io
Ph: 949.409.1264